
Espial IDS
In the past semester of university I wrote a white paper which includes an overview of Intrusion Detection Systems and an implementation written in C++ that uses dynamic signature rules from file that detects intrusions through parsing of the output from TCPDump. I put a lot of thought into the rule architecture for efficiency and reliability and does a large amount of string matching based on array locations and rule lookups using the STL Map resulting in O(n log n) efficiency, differentiating based on the amount of rules implemented. The paper can be seen below:
May 18th2012
Intrusion Detection System Overview & Implementation
1.0 Intrusion Detection Systems Overview
1.1 Introduction
Information system based attacks escalated to an all time high during 2011, proclaimed by security professionals as the “Year of the hack”. [1] The ongoing onslaught of data breaches that are being widely publicized and are tarnishing company images, and reputations. Information system breaches presented in large numbers have shown that not enough is being done to prevent these breaches from occurring, and detecting these breaches once they have occurred.
Since our current security standpoint and methodologies seem to be losing in the cat and mouse game of the prevention of breaches, the next logical step is the detection of these attacks and stopping them while/once they occur. This involves the implementation of a phenomenon called the Intrusion Detection System. Known commonly as an IDS, an Intrusion Detection System would act, from an analogic perspective, act as an alarm system that would detect breaches in network-based hosts and infrastructure. It utilizes information attained from hosts and network traffic to determine if a possible data breach has occurred. Typically once a data breach is detected, a notification will be logged and/or sent to a System Administrator for further investigation. [2] The following sections will discuss IDS sub-systems, IDS detection techniques, the main goal of an IDS, and the application areas of an IDS.
1.2 IDS Sub-Systems
An Intrusion Detection System typically involves the following sub-systems:
-
Network Intrusion Detection System (NIDS) – This sub-system involves the analyses of network traffic from an entire subnet of a network. If certain data or a collection of data pertains to a breach, a notification is made to an authority, typically a System Administrator to conduct further actions. [2]
-
Node Network Intrusion Detection System (NNIDS) – This system involves the same characteristics of NIDS, however, only involves the analysis of traffic for a single node on the network. [2]
-
Host Intrusion Detection System (HIDS) – This system taking a “snapshot” of the current system’s critical infrastructure and using this snapshot in comparison to detect changes and intrusions. This snapshot is typically comprised of the filesystem, critical binaries (eg. the login binary in Unix or winlogon.exe in Windows) in which if these are modified they will cause a notification to be sent to an appropriate authority. [2]
1.3 IDS Detection Techniques
NIDS and NNIDS each involve the analysis of network traffic. There are two detection techniques for determining whether or not traffic should trigger an incident:
-
Statistical-based IDS – This form of IDS determines, statistically, whether traffic is anomalous through analysis of large amounts of “normal” traffic on a network. “Normal” traffic is typically comprised of commonly connected ports, commonly used protocols etc. If an anomaly is detected, a notification is sent to an appropriate authority for further investigation. This can involve the use of thresholds for frequency of occurrences of various events and establishing a profile of past user activity in order to compare against traffic to establish anomalies. [3][5] The metrics involved can consist of:
-
Counters – These keep track of the frequency of certain actions. Such as the number of logins within an interval of time or the number of password failures that have occurred.
-
Gauges – These gauge certain aspects of user applications, such as the number of logical connections assigned or the number of queued outgoing messages.
-
Interval Timers – These keep track of the length of time between two events that could be related. Such as the length of time between successive logins.
-
Resource Utilization – This would keep track of the number of resources being used, such as the amount of bandwidth being consumed by a user.[5]
Based on the metrics taken, anomalies can be detected through analysis with statistical tests:
-
Mean & Standard Deviation – Using the historical average and variability of a parameter to establish an anomaly.
-
Multi-variate – Considering the relationship between two or more parameters to establish an anomaly.
-
Markov Process – Based on the analysis of the parameters change between states to establish an anomaly.
-
Time Series – Time-interval based analysis to see if a sequence of events occur too quickly or too slowly. [5]
-
Signature-based IDS – This form of IDS determines if network traffic is being caused by a data breach through comparisons with pre-constructed attack patterns known as signatures. These signatures will be constructed through analysis of known attack patterns/traffic and produce a signature string that will identify these types of traffic when seen by the IDS. Once a match is made, a notification is sent to an appropriate authority for further investigation. [3] [5]
-
Rule-based IDS – This involves creating rule-sets that can be used to determine if the activities of a user is that of an intruder. This relates to HIDS as well since it would be detecting anomalies on the current user’s system that are out of the ordinary based on established rules. Such as user’s should not be reading/writing to files in other user’s directories, abnormal access times (after work hours, in the middle of the night) etc. [5]
1.4 Main Goal
The main goal of an IDS is to produce the least amount of “False Positives”, the most amount of “True Positives”, produce the least amount of “False Negatives”, and the most amount of “True Negatives”. As for what can be taken easily from these terminologies, a “False Positive” would be the production of a notification for an event that is not actually a breach or an attempt at a breach, which would lead a System Administrator in a false investigation or cause unwanted noise in logs/notifications. A “False Negative” would be a circumstance where a breach or an attempt at a breach has occurred and the IDS does not produce a notification. This would obviously be the most unwanted since this is essentially the IDS being bypassed by an adversary and a breach could go unnoticed. Thus, the opposites of these being a “True Positive” which would involve the detection of a breach and/or attempt at a breach and a proper notification being sent and a “True Negative” where unwanted notifications are not produced for normal traffic being checked by the IDS. [2]
1.4 Applications
Areas that an IDS can be applied can be derived from the nature of the system itself and the sub-systems it is comprised of. Its application of an IDS system would differ based on the size of the organization applying it.
An IDS typically contains multiple “sensors” used to monitor network traffic to detect anomalies. There are two types of sensors:
-
Inline Sensors – this type of sensor is inserted into the network in conjunction with an available network device such as a switch. This results in the actual network traffic passing through the device before it meets its destination. This is advantageous since only one hardware based device is required and there is only one copy of the traffic made. Typically this would be done in order to block malicious traffic once detected. This type of sensor would be more targeted towards an IPS (Intrusion Prevention System) where it would perform both detection and prevention of malicious activities. Typically involving deep packet inspection results in slower network traffic flow. [4]
-
Passive Sensors – this more commonly used sensor involves monitoring a copy of the traffic. This results in the actual traffic not passing through the device. From a traffic flow efficiency point of view, this is more efficient than in inline sensor since packet inspection is not occurring prior to a packet continuing to its destination. [4]
A simple example would be on a home based network a sensor would be placed between a home router/modem (typically known as multi-layered switch since it does both routing and switching of packets) and the rest of the workstations on the network, thus monitoring incoming and outgoing traffic. If there was a single workstation it would be between the workstation and the modem connecting it to the internet (obviously in this situation a NNIDS and/or HIDS would only be necessary). A more complex situation, such as in a network environment, is shown in the following diagram:
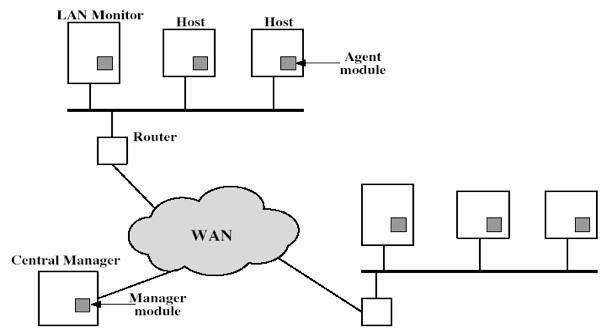
Example 1.4.1 – Distributed Intrusion Detection Architecture [5]
This situation involves a distributed IDS architecture, in which the “LAN Monitor” depicted would be an inline or passive sensor which monitors incoming/outgoing traffic for a number of hosts. The agent module depicts an HIDS for each of the running hosts on the network. All of these distributed sensors would all report to a “Central Manager” is a node which contains the “Manager Module” that would collect and organize notifications from all other sensors and distribute notifications as needed. [5] Typically in large infrastructures this system would be able to produce the best results from the cooperation of various sensors and the Central Management system.
2.0 Idea Overview
2.1 Implementation Strategy
My ideas varied throughout the production of this project. I needed to decide which kind of IDS I should implement, and how I should go about implementing it. NIDS intrigued me immensely since they interpret network traffic in real time, as apposed to simply checking files/structures/data iteratively as an HIDS would. My final decision was to write a NNIDS for simplicity and to challenge myself with the task of interpreting network traffic against established rules.
I was contemplating writing my own network sniffer to parse network data. Due to time constraints and the complexity of the task I decided to utilize a widely known and commonly used tool Tcpdump. As the Man page states “Tcpdump prints out a description of the contents of packets on a network interface that match the boolean expression.” It is widely used since it comes by default on many Unix/Linux based systems, and it is also included in OSX by default. Tcpdump simply produces text based output in which was perfect for what I was trying to accomplish since I needed data to parse through and produce alerts accordingly. The language I decided to use was C++ since this is the language I am currently studying, it is powerful from an efficiency standpoint and I wanted to expand my knowledge in this language.
2.2 Parsing Tcpdump Output & Data Structures
Parsing the data out of the program running was a fairly simple task. A pipe can be established in C++ from an executed process and output can be taken and read into a running program through a buffer.
The next task was handling the data being brought in through the buffer. Typically I could have simply read in each line in a linear fashion, then have sent to a function to compare on string matches and printed out alerts accordingly. The efficiency of an operation of this nature would be the product of the string matching algorithm used and the length of the input string. A brute force method would result in the efficiency class of O(n^2), n being the length of the input string (the line from the Tcpdump), and this would be done for each established rule, resulting in O(m(n^2)) efficiency, m being the number of rules currently in memory. To put this into perspective, if we had an input string (these coming very frequently) of 40 characters, and with 20 rules this would result in:
40^2 = 160 (every possible string match)
160*20 = 3200
That is 3200 comparisons for each line in this circumstance, which is a substantial load on the system for every single line that comes in from the network. Obviously through a more efficient string matching algorithm the efficiency would be much better, however, a substantial load would still occur on the system. For this reason I put a substantial amount of time and effort into devising the most efficient and reliable method of string matching based on input strings in combination with a dynamic list of established rules. This would be in order to avoid a DOS of the IDS itself through an attacker simply overloading it with traffic or simply crashing on a busy network.
My end solution involved first, reading in a set of rules from file with an established notation. This notation is as follows:
ArrayIndexForMatch MatchingString AlertMessage ForeignIPArrayIndex(If Any)
This involves the user creating a rule based on tcpdump -Aoutput. The -A parameter allows packets to be printed in readable ASCII format which is suitable for string matching of various types of traffic. The Tcpdump output is read into a string array from the buffer, and the string array is sent to be checked by the rules.
The rule is based on array indexes in order to be compatible with the established rule data structures. In order for efficiency I decided to use the C++ STL Map which is an associative container that allows two types of data to be associated – these being both strings in this case. When rules are imported, a dynamic linked list is created in accordance to the rule data. Each node in the linked list contains an integer indicating the index of the string to be matched and each also contains a Map of all of the rules for this certain index. If the index node already exists when more rules are imported, they are simply set into the map of that index node.
The reason that there is a Map for each of the rules within a certain index is for efficiency. The Map container uses the binary search algorithm with the efficiency class of O(log n) [6]. This results in the total traversal and comparisons of this algorithm is minimal since with every line that comes in, it takes it into an array, supplies the array to a search function, linearly goes through each index node, takes the string to be matched based on the index node from the string provided, and compares it with binary search to each rule in the map. This results in the total efficiency class of O(m(log n)) for each line that comes in. In our circumstance above it results in the following efficiency:
log(20) = ~1.30 (in this circumstance the number of rules)
This would be multiplied by the number of differentnodes in the linked list that had to be traversed. The length of the input string wouldn’t actually matter. For instance if we had 10 different nodes of different matching indexes the efficiency would be:
1.30 * 10 = 13
If there were simply only rules corresponding to one index such as 0, the efficiency would be:
~1.30 (for 20 rules)
This is a substantial difference to 3200 per line which would result in very fast string comparisons. There are some drawbacks, however. At this point the algorithm for reading and comparing indexes are only for single strings, however, this could be easily fixed with adjustments to the algorithm to read in a number of strings based on the rules of each line.
I have also established built in rules that have algorithms in and of themselves, these include rules for port scanning and other events that do not simply involve string matching.
2.3 Choosing a Name
All great programs typically (sometimes rarely) have a well chosen name. In this circumstance I decided to look up the synonyms of “Spying” or “Watching”. This resulted in this IDS having the name “Espial” which simply means “The act of spying” or “The act of keeping watch; observation”. Since, in turn, the program watches and interprets packets seamlessly (or almost seamlessly).
3.0 User Manual
3.1 Main Menu
For simplicity I have made the program with a text based interface that is ran from the command line. The main menu is as follows:
-----------------------
1) Start Espial IDS
2) Import Rule(s)
3) List Current Rule(s)
4) About Espial IDS
5) Quit
-----------------------
Choice:
From this menu the use can choose to start the IDS, import more rules from file, list the current rules in memory, view the about page, or quit the program.
3.2 Start Espial IDS
This will start the IDS program and begin to interpret traffic with established rules. If there are no rules currently loaded, an error message with appear and the IDS will not start. When a rule is encountered, the accompanying alert will be displayed to the screen and written to the logs.db file for further review. If there is an accompanied foreign IP address indicated in the rule, this will be logged as well.
3.3 Making & Importing Rules
If the Import Rule option is selected the user will be prompted for a file name. This should be a valid file with the rules in the following format:
ArrayIndexForMatch MatchingString AlertMessage ForeignIPArrayIndex(If Any)
The rules have to be in this format in order to work and operate successfully with the established algorithms. In order for a rule to be made, Tcpdump output has to be analyzed and used accordingly. For example, if we have the following Tcpdump output of a ping echo request:
01:34:04.725144 IP 172.16.40.1 > 172.16.40.142: ICMP echo request, id 58989, seq 10, length 64
E..T....@.....(...(......m.
O..L.....
.................. !"#$%&'()*+,-./01234567
If a match was to be made on any kind of ping request, this would result in the following rule:
5 ICMP PING! 2
This would result in the an alert being made upon every ping request being sent to that host, the alert message would be “PING!” and the foreign IP address in this circumstance would be 172.16.40.1.
The file name should then be typed in and the rules will be imported accordingly into memory. Espial will display “Rule Added!” when this is done successfully.
3.4 List Current Rules
When this option is selected, it will simply list all of the rules currently in memory. For example:
-----------------------
1) Start Espial IDS
2) Import Rule(s)
3) List Current Rule(s)
4) About Espial IDS
5) Quit
-----------------------
Choice:
3
Match: IP Alert: IPPacket!
Match: google.com Alert: FoundGoogle!
3.5 About & Quit
These options will simply show the about page for Espial and quit the program accordingly.
4.0 Conclusion
There is still so much room for improvement in this IDS implementation and there is a world of improvement still needed in the field of intrusion detection itself. This is an important aspect of network security that has to be seriously considered in this day and age due to the ever expanding digital network of the internet and the constant growing complexity of threats that have to thwarted. These types of algorithms could also possibly be considered for a number of applications where single component string matching is needed based on a number of rule-sets such as malware identification/classification. Throughout this project I have tried to implement the most efficient and practical techniques for intrusion detection to take place and have, in doing so, learned an immense amount about networking, security based technologies and C++ programming techniques.
5.0 References
[1] Fred Donovan (2011), “Year of the Hack”, InfoSecurity, [Accessed: May 5th, 2012] Website: http://www.infosecurity-magazine.com/view/22481/year-of-the-hack-/
[2] Danny Rosenblum (2001), “Understanding Intrusion Detection Systems”, SANS Institute InfoSec Reading Room, [Accessed: May 5th, 2012] Website: http://www.infosecurity-magazine.com/view/22481/year-of-the-hack-/
[3]Mattord, Verma (2008), “Principles of Information Security”, Course Technology,. pp. 290–301
[4] Lawrie Brown (2008), “Computer Security Principles and Practice”, William Stallings, Pearson Education, pp. 190-197
[5] William Stallings (2010), “Cryptography and Network Security: Principles and Practice (5thEdition), William Stallings, Chapter 20
[6] Pete Becker (2011), Working Draft, Standard For Programming Language C++, Roundhouse Consulting Ltd.
Thanks for reading :)
~Josh